我们现在使用钱包,无论是软件钱包还是硬件钱包,第一步操作就是让选择生成助记词还是导入助记词,对于新人来说,一定是生成助记词,那这个助记词是怎么生成呢?
我们在前一篇文章中已经介绍过了技术总览,Web3 – 摩天大楼的地基 – 钱包在做什么?- 助记词,本篇详细讨论下助记词的生成步骤。
BIP39
助记词是有共识性标准的,几乎所有的钱包和链都会遵守,文件在这里 https://github.com/bitcoin/bips/blob/master/bip-0039.mediawiki。BIP39 规定了生成的步骤和提供了标准单词表。
OSKey 实现完全遵循 BIP39 规范,并完整通过提供的测试向量。
助记词是什么?
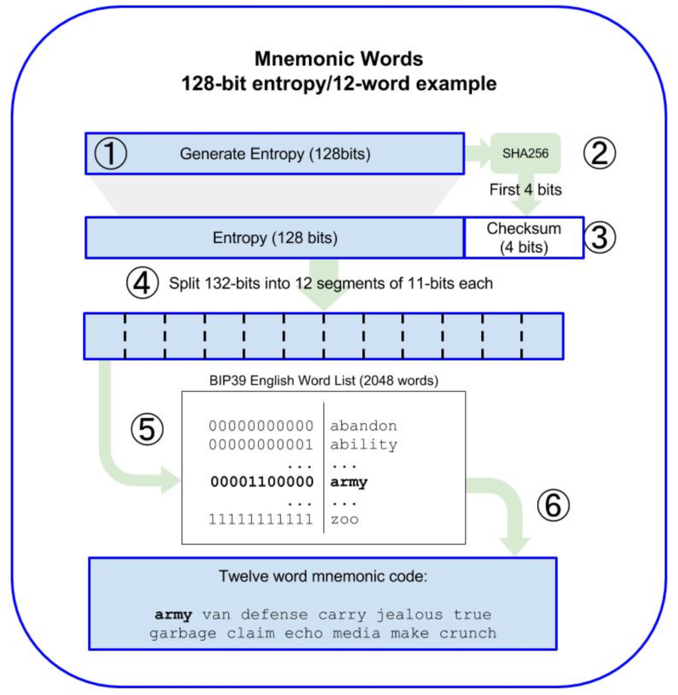
助记词的本质是一段随机数,助记词用人类可读的方式记录这个随机数。单词数越多的助记词对应越长的随机数,安全性越高。
我们先看下规范中的描述:
MS: 助记词单词个数,数量在 12-24 之间按 3 个单词递增。
ENT: 随机数长度
CS: 校验长度
CS = ENT / 32
MS = (ENT + CS) / 11
| ENT | CS | ENT+CS | MS |
+-------+----+--------+------+
| 128 | 4 | 132 | 12 |
| 160 | 5 | 165 | 15 |
| 192 | 6 | 198 | 18 |
| 224 | 7 | 231 | 21 |
| 256 | 8 | 264 | 24 |如果是需要 12 个单词的助记词,对应 128 bits 的随机数,对这个随机数进行 SHA256,取 hash 的 4 bits 作为校验位,总长度 132 bits。
单词是如何对应到随机数的?
上面提到的 ENT(随机数)+ CS(校验)总是 11 的倍数,把它们按照每组 11 个 bit 分组,把 11 个 bit 的 2 进制转为 10 进制,我们会得到 0-2047,这些数字对应到单词表就可以得到助记词。
可以看到最后一个单词是带校验的,所以不是从单词表取对应数量的单词就是助记词。
这是单词表,对应各个语言,为了通用性,我们一般选择英语。https://github.com/bitcoin/bips/tree/master/bip-0039
OSKey 的随机数
计算机如何能够提供一个足够随机的随机熵一直是一个难题,多个钱包因为随机数生成的问题造成用户的资金损失。
OSKey 使用硬件随机数生成器(RNG)来获取随机数,芯片的硬件随机数生成器一般都是符合工业标准的。采用多种方式保证足够随机。
如果芯片没有硬件支持的随机数生成器,则 OSKey 这时候会回退到基于时间的伪随机,如果 OSKey 提示芯片不具备硬件随机数生成器,则生成过程不够安全。
OSKey 助记词的实现
对于助记词的实现在这里,我们解释下生成相关的方法。
https://github.com/butterfly-community/oskey-lib-core/blob/main/wallet/src/mnemonic.rs
Mnemonic::from_phrase(phrase: &str) -> Result<Self>
输入助记词,还原回原始熵并校验校验位,导入
Mnemonic::from_entropy(entropy: &[u8]) -> Result<Self, anyhow::Error>
从随机数生成助记词,提供需要的原始熵。
Mnemonic:: entropy_to_bits(entropy: &[u8]) -> Result<BitVec>
从原始熵生成按 11 个 bit 分组的助记词序号
Mnemonic::bits_to_words(bits: &BitVec) -> Result<Vec<&'static str, 24>>
从助记词序号列表中取出对应的单词,最多 24 个。
OSKey 导入助记词的实现
我们从上面助记词的生成过程已经知晓,不是任意一组单词都是助记词,最后一个单词可以校验输入的单词是否正确。
完整实现中,我们需要执行一个反向的过程,还原回原始熵然后计算一遍校验,对比校验是否正确,如果正确则开始下一步。
关于下一步的实现我们在接下来的 HD Wallet 篇中讨论。